Interpreteren van data is vaak een kunst op zich, zeker als u niet bekend bent met data analyses. Het kan lastig zijn om vat te krijgen op de gepresenteerde visualisaties, of om concrete conclusies te vormen op basis van een analyse.
Na een data analyse worden vaak visualisaties gepresenteerd, op basis waarvan verdere conclusies getrokken worden. Wij geven u 5 tips om hier mee aan de slag te gaan, en deze visualisatie resultaten op de juiste manier te interpreteren.
Het vak van data science houdt zich bezig met het vinden van patronen. Door data slim te ordernen, groeperen en transformeren kunnen verschijnen vele verschillende patronen uit de data. Data scientists focussen zich op het zichtbaar maken van deze patronen. Goede resultaten van een data analyse maken deze patronen zichtbaar en inzichtelijk.
In de statistiek is een bekend voorbeeld een scatterplot of spreidingsdiagram. In zo’n diagram zijn twee variabelen uitgezet tegen over elkaar en is elk stipje een specifiek datapunt. Als er sprake is van een linear verband is dit direct zichtbaar, doordat zich een wolk vormt met een specifieke vorm. Een patroon.
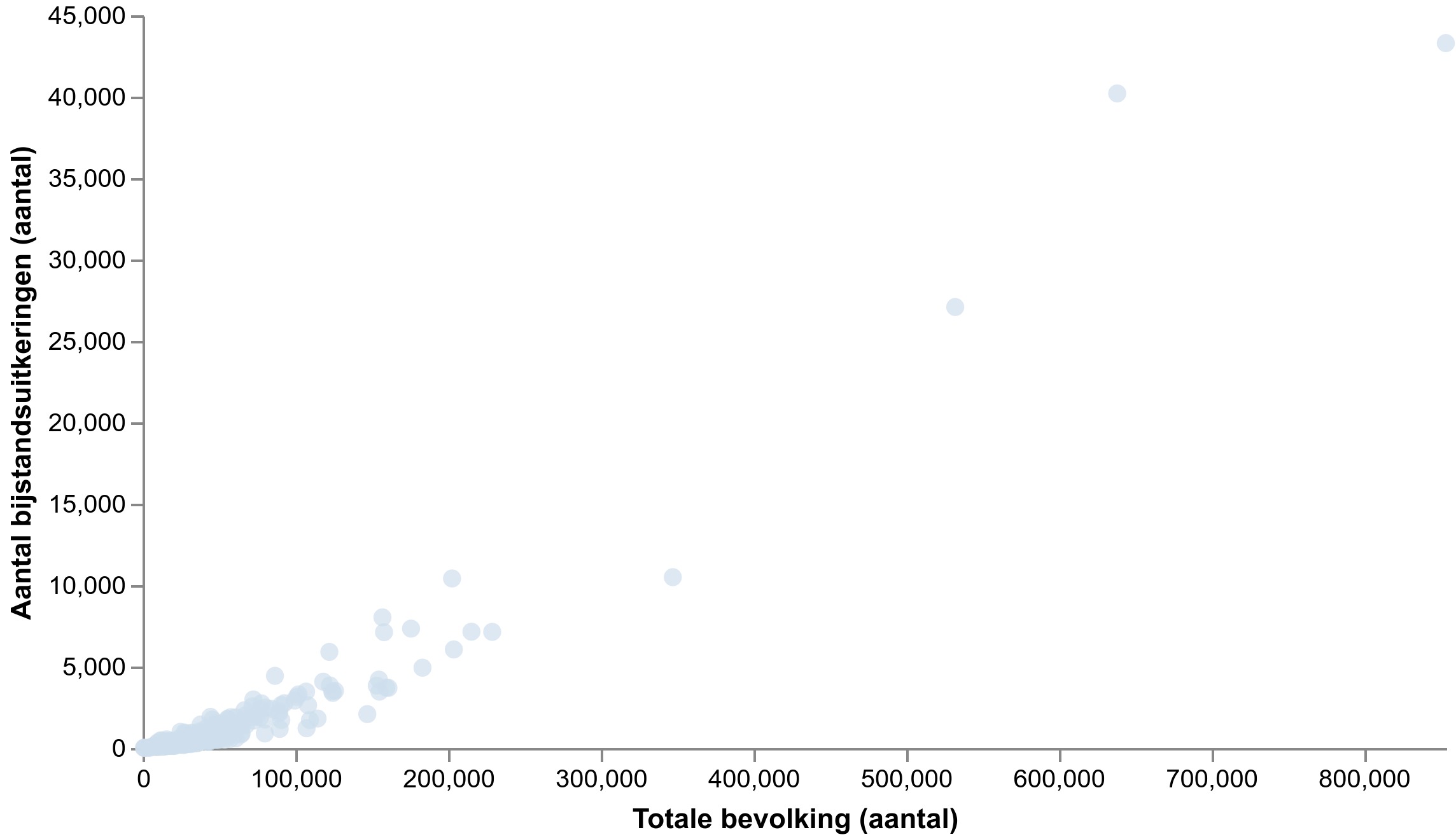
Bron: CBS, visualisatie gemaakt met Data-Kompas
Dit is een voorbeeld van zo een grafiek. We zien hier de relatie tussen het aantal inwoners “Totale bevolking” en aantal bijstandsuitkeringen, per gemeente. Dit wil zeggen dat elk bolletje een representatie is van een gemeente, en er in totaal net zoveel bolletjes zijn als gemeenten (bijna 400).
Kijkend naar patronen zien we het volgende:
Wat kunt u verder ontdekkken?
Het is aan beleidsmakers om deze patronen verder te interpreteren. In een trendgrafiek kunnen er dalende of stijgende lijnen zijn, wat een indicatie is dat de meetwaarde gedaald of gestegen in de tijd. Is dit gunstig voor uw organisatie, of juist niet?
In het voorbeeld van boven lijkt er een sterk verband gevonden te zijn voor het aantal bijstandsuitkeringen. Mooi! Dit kunnen we dus gebruiken om grip te krijgen op het aantal mensen in de bijstand.
Of niet? Het is vrij logisch dat het aantal inwoners in gemeenten een grote invloed heeft op het aantal bijstandsuitkeringen. Eigenlijk zegt bovenstaande grafiek dus niet zoveel, al zijn er wel duidelijke patronen zichtbaar.
Veel interessanter is het als we het aantal bijstandsuitkeringen per inwoner vergelijken met het percentage koopwoningen.
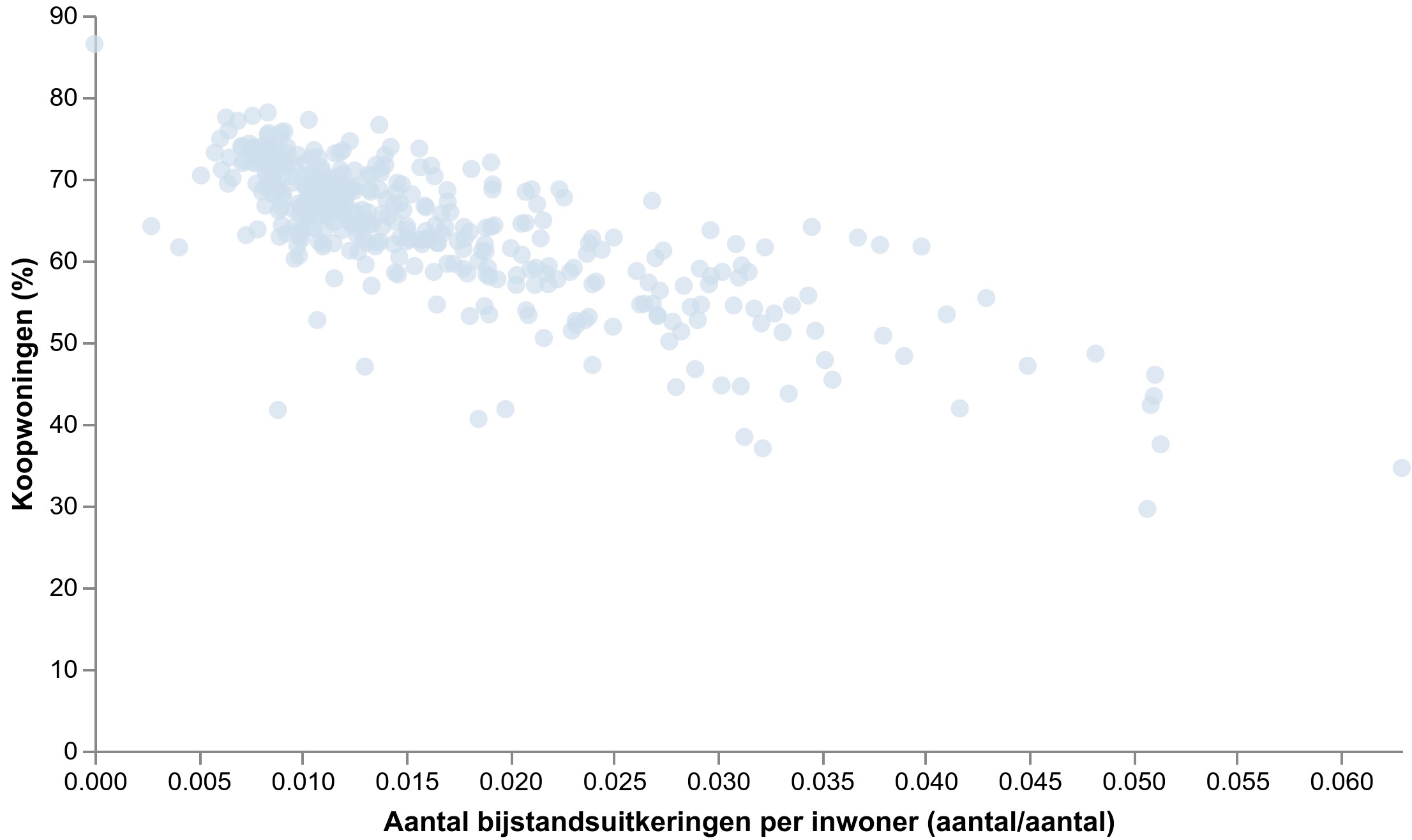
Bron: CBS, visualisatie gemaakt met Data-Kompas
Wat kunnen we hier uit concluderen? Opnieuw is er correlatie, maar is er een causaal verband?
Desalniettemin kunnen deze patronen vertekenen. Op basis van de operaties die een data analyist heeft uitgevoerd kunnen sommige patronen wel of niet onstaan.
Ons advies is om in ieder geval te letten op:
In een toekomstige blog zullen we dieper in gaan op deze valkuilen.
De belangrijkste identificaties van patronen vinden plaats doordat mensen met een specifiek beeld kijken naar de data. Experts binnen gemeenten kunnen wellicht patronen verklaren op het gebied van woningen en bijstand, of kunnen aantonen welke van de twee het gevolg is van de ander.
Deze domein kennis is van cruciaal belang om beleid te vormen op basis van deze visualisaties.
Onze laatste tip is om de discussie aan te gaan. Een beroemde quote:
“If you torture the data long enough, it will confess” - Ronald Coase
Tijdens een data analyse gaat het er niet om wie gelijk heeft. Het doel is om samen uit te zoeken wat de waarheid is, en op basis van deze waarheid conclusies te vormen. Elke visualisatie is slechts een bevooroordeelde representatie van de werkelijkheid, welke juist geinterpreteerd moet worden.
Door met zowel de data scientist, als domein experts in gesprek te gaan wordt duidelijk wat relaties zijn tussen visualisaties, welke elementen cruciaal zijn, en vooral welke data wel en welke data niet compleet juist is. Op basis van een specifieke bias zien sommige personen patronen juist wel of niet, of kunnen deze matchen met hun eigen kennis. Door de discussie aan te gaan wordt meer kennis zichtbaar uit de data.
Bent u geïnteresseerd in meer van deze tips & tricks of adviezen voor data interpretatie? De komende weken zullen wij meer bloggen over valkuilen bij data interpretatie, specifieke visualisatie typen, methoden om uw eigen data te vergelijken met open data, en nog veel meer! Volg ons op op twitter, voor alle laatste updates.
Of vraag informatie aan voor de introductie workshop ‘data en beleid’, om helemaal up-to-speed te zijn op het gebied van data en beleid.

